Sony’s indirect wholly-owned Indian subsidiary, Sony Pictures Network India (SPNI) has built data lakes on Amazon Web Services (AWS) to help modernise all its downstream applications.
SPNI’s head of infrastructure and analytics, Mahesh Patil, told the recent AWS Summit India 2022 that the use of AWS services had helped the company focus more on building advanced use cases and, at the same time, “extensively” enhance customer experience, among other business outcomes.
Patil added that the company has also solved the complex problem of extracting Broadcast and Research Council (BARC) data on viewership using the YUMI application and transforming the data at scale.
“Modernising application and cloud-native services provided us faster time to market and the pay-as-you-go model decreased total cost of ownership,” he said.
SPNI embarked on its digital transformation journey in 2021 with AWS and other partners.
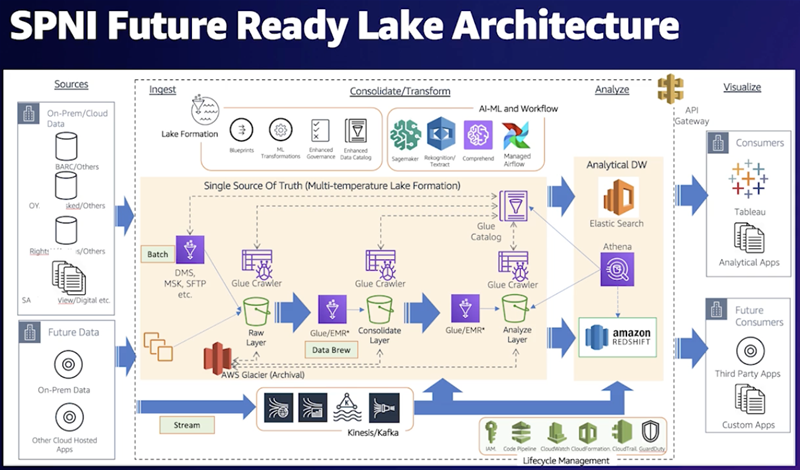
The large and complex nature of this modernisation project required services spanning nine different tracks including a data lake, machine learning operations (ML Ops), SAP S4/HANA, robotic process automation, and middleware business logic deployments using AWS Step Functions, broadcasting management systems, and much more.
While SPNI’s existing infrastructure couldn’t support the latest use cases, the tech team decided to build an edge competent data analytics platform that would not only support new use cases but also provide unified access to data, comprehensive analytics and security for all business units.
“For instance, our artificial intelligence (AI) and machine learning platforms built with AWS can schedule TV shows based on ratings, popularity and other analytics,” said Patil.
‘Future ready’ architecture
Patil said when the team switched to AWS it expected the data lake to act as the foundation layer for AI/ML implementation and the new platform to provide automated deployments.
The focus was not simply on integrating a data lake with a data warehouse, but rather on integrating a data lake, a data warehouse and purpose-built stores, enabling unified governance and easy data movement.
“We designed the future-ready data lake architecture based on Lambda pattern for big data problems,” Patil said
SPNI’s enterprise data lake architecture supports multiple types of data sources, including structured, semi-structured and unstructured.
It has more than 23 source systems covering sales and distribution, content, production and operations, broadcasting, enterprise applications, and digital publishing.
The tech teams extended the data lake platform by ingesting data from its master data management (MDM) system, vendor risk management (VRM) and employee data for HR operations.
The data was stored, curated and made available on Amazon S3 which serves as a data lake for all downstream applications and analytics in a seamless fashion using several ingestion mechanisms.
“The set-up scales to more than 700 data sets with 1800 plus tables, handling terabytes of data… The architecture established a common injection site to bring the data to a data lake that will support different mechanisms,” he explained.
Patil said SPNI was able to reduce the extract, transform and load (ETL) execution timelines by nearly 80 percent compared to the existing on-premises data warehouse.
Additionally, it has also provided the flexibility to scale the critical workload automatically based on a spike, using the serverless architecture.
“We achieved 85 percent automation in data pipeline CI/CD environment deployment with the new edge enterprise data lake architecture that is highly robust.”
Patil said all the data pipelines were entirely automated by AWS and they had set up a landing zone to put necessary guardrails across the organisation.
“A single click deployment cloud formation template has been created and is used to set up additional environments such as development, staging, pre-production and others… The architecture is completely scalable to address any future requirements, covering real-time data processing unstructured data and video analytics,” he explained.
YUMI analytics
YUMI Analytics, an advanced software with respect to television measurement and insights, is a critical source system that does not allow cloning and imaging, and cannot scale PostgreSQL procedures, Patil said.
The AWS tech team devised a workaround to clone the YUMI application by copying the day directory structure from Amazon EC2 to another application, thereby saving a lot of effort in configuring the application, he added.
Patil said with further steps, the company has been able to enable zero code file maintenance and availability, eliminating bad scripts by reading the flat datasets.
"We have also converted the PostgreSQL procedures into scalable and resource-optimised AWS Glue jobs," he said.
As a key objective, Patil suggested firms should create a solid business case and build a roadmap to achieve incremental gains.
“The recipe for digital transformation is centred around people, process and technology… Setting clear, measurable KPIs (key performance indicators) can help assess and move forward on the journey,” he added.








